AI Agents to evaluate Coding Assessments and Hackathons in hiring
Published on January 23, 2025
In my previous role at Acquia, we had a coding assignment that every new recruit in our India-based team was required to complete. The task was a take-home exercise where candidates had to build an interface based on a provided set of specifications. Akin to the Odin Project’s exercise—which requires candidates to construct a shopping cart using product data from the Fake Store API.
However, when different engineers reviewed these submissions, the feedback often lacked consistency. The review process was subjective, with some reviewers placing more weight on certain aspects, while others might heavily penalize candidates for different reasons. To bring some objectivity to the process, we devised a scorecard—a checklist that allowed reviewers to evaluate submissions against a clear set of criteria. This worked well, but the challenge was that each review would take about an hour as engineers assessed various aspects and scored them accordingly.
For a few submissions per month, this process was manageable. But when mass-hiring became the goal—such as during a recent internship drive that I ran—the task of evaluating hundreds of take-home assignments becomes increasingly laborious and resource-intensive. Of course, other means of evaluation could help us filter through the candidates, but coding exercises are integral to the process—they’re a vital part of the selection.
I always wished there was a way to scale this process. The question I found myself asking was: Why not automate the evaluation of these code submissions with test cases? However, the reality was far more complex. Until recently, UI automation frameworks such as Playwright relied on CSS selectors or Xpath or the text labels of UI elements to interact with them. When it comes to exercises like these—where candidates are given some creative freedom in the design and placement of elements—such automation techniques would fall short. After all, candidates would rarely assign the same ID or label to each element, leading to mismatches and failure in the automation.
Having built numerous AI agents using CrewAI to automate a broad range of tasks, it was an obvious thought:
What if AI agents are now advanced enough to evaluate websites based on flexible and not-so-specific requirements?
After all, each submission might differ vastly in design, layout, and the placement of UI elements.
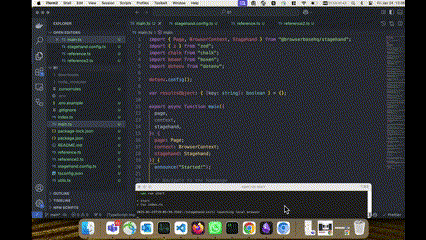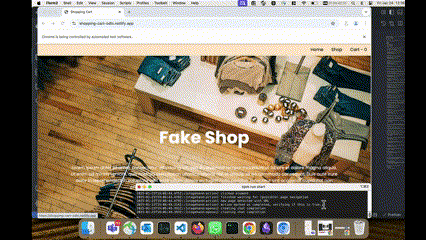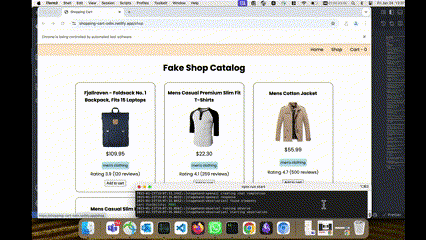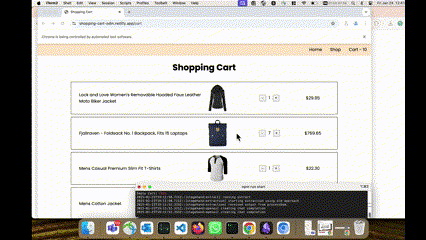
After a short exploration of browser tools and headless frameworks for AI agents, I decided to experiment with Stagehand, primarily driven by my admiration for Playwright. With fewer than 100 lines of code, I was able to create an AI agent capable of evaluating live websites built against Odin Project specifications like this one found in this google search, validating them against a set of predefined test cases, and then scoring the submissions accordingly.
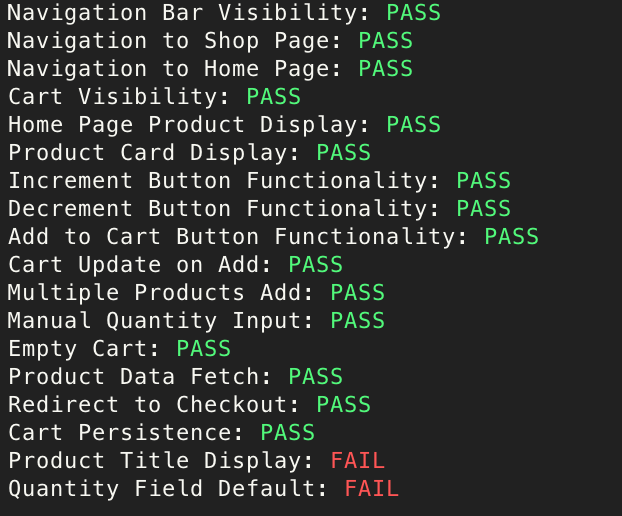
This development has the potential to revolutionize how we approach the evaluation of coding assignments, especially those that can't be validated by unit test cases like those involving building frontend interfaces. For example, with 100 submissions, I can quickly narrow the pool down to the top 10 candidates for further manual review or discussion.
So, how does it work?
In addition to the standard Playwright functions—such as page.click(selector) or page.fill(selector, value) — Stagehand provides additional functionalities like page.act(), page.observe(), and page.extract(). These functions are designed to take natural language input and perform actions on UI elements.
For instance, to click the "Add to Cart" button for the first product in the listing, Playwright would traditionally use code like this: 
But this approach would fail across different submissions, as the CSS identifiers would likely differ for each candidate's unique UI design.
With Stagehand, however, the code looks like this:

This approach is adaptable—it works regardless of the CSS selectors, XPath, or even the button’s label. As long as the action is reasonably clear, such as a "+" symbol to signify an "Add to Cart" button, Stagehand’s AI can identify and interact with it.
This is a game-changer. The implications for how take-home assignments and hackathons are evaluated are profound. We now have the potential to automate and scale the process, saving invaluable time and resources, while ensuring consistent and unbiased evaluation.
Evaluation platforms like Mettl have a clear opportunity to include such automation into UI coding tasks in online tests.
On a personal front, I'd probably dedicate an upcoming weekend to built a set of AI agents to automate filling in my timesheets, filing expense reports, and approving invoices that should save a bunch of hours every week!